We are interested in the following infinite-horizon optimal control problem
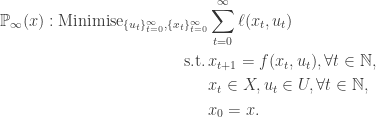
We ask under what conditions the dynamic programming value iterates converge. We will state and prove a useful convergence theorem, but first we need to state some useful definitions.
Firstly, we consider the discrete-time dynamical system
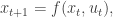
with state 


Starting from an initial state 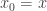
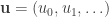

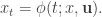
The objective is to determine a sequence 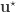

where 

We say that a sequence 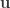
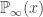

where 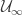
The set of feasible states is defined as
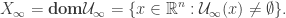
By definition, 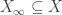
The infinite-horizon optimal control problem can be written as

Define the value function of 
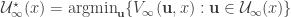
Important: 
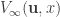
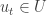

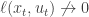

Therefore,
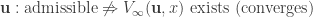
and
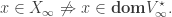
but
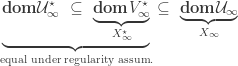
The infinite-horizon constrained OCP can be written as

where 

where

Note that function
Value Iteration of the Dynamic Programming Procedure
The Value Iteration for determining

where 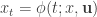
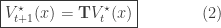
starting with a function 
![V:\mathbb{R}^n\to[0, \infty]](https://s0.wp.com/latex.php?latex=V%3A%5Cmathbb%7BR%7D%5En%5Cto%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Under certain conditions (on 
A notable property of 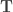

As a sidenote, recall that in the above equation, 
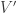



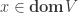
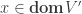

Suppose 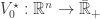
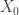
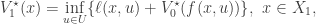
where

Recursively,
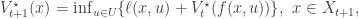
where
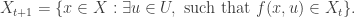
Note: 
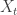

Hereafter we shall assume that for all 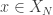

A Note on Notation
We have denoted the DP iterates by 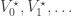
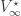



Without any assumptions on the problem data we don’t know whether the limit
Spoilers: under certain conditions (some weak regularity conditions plus some conditions on 
Bellman’s Equation
The celebrated Bellman’s equation states that 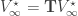
Under certain conditions, the value iteration converges to a limit,
The following theorem states some important facts about the set of fixed points of the dynamic programming operator, 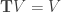
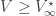
Theorem 1 (Fixed points of DP operator). Suppose that 
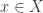
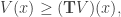
where the minimum is attained and 


where 
Proof. Clearly, by the definition of 
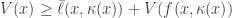

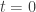


and taking 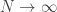

Since 
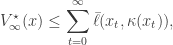
which completes the proof.
Convergence of Value Iteration
In this last section we will show that the DP iterates converge to the value function of the infinite-horizon optimal control problem when 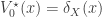
The theorem is proven by leveraging the monotonicity properties of
Theorem 2 (Convergence of DP iterations). Suppose that
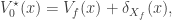
where 
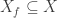
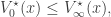
then 


Proof. Let us first prove this for 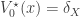
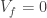
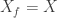

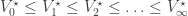

From Theorem 1, this implies that 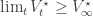
Let us denote the above sequence of functions by 
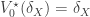
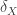
Suppose that 
From the monotonicity of

Taking the limit as 
